Scale with rate limiters

I’m a software ninja 🥷 who loves abstractions and spread functional programming everywhere. I've over 2 years of experience and I'm based in Delhi, India🇮🇳
Availability and reliability are important parts of systems; if you are exposing an API, it should be available and reliable to consumers.
You must have experienced this when you grew your API endpoints and received more traffic. It is okay as the business grows, but the growth brings bad actors into the system, and those actors may send too many requests and slow down your systems, or you may entirely shut them down.
Rate-limiting helps you solve the following:
A bad user may send loads of requests, which should not affect any genuine user.
A user is sending you low-priority requests that are blocking high-priority requests. The system prioritizes high-priority requests over low-priority requests. This is called load shedding.
Sometimes, if the system is wrong internally (a resource crunch) and you cannot serve all your regular traffic, you may want to drop low-priority requests in favor of high-priority requests.
Some common types of rate limiters are:
Request rate limiter
Concurrent rate limiter
Fleet rate limiter
Worker utilization load shedder
Request Rate Limiter
A rate limiter that limits requests for a user to N times per second. Usually, it is put per API, and the user is trained to send only limited requests per second for that API.
For example, a user can only log in 5 times per minute.
// Limit user to 5 requests in 5 minutes (5 * 60 seconds)
@RateLimit({ threshold: 5, duration: 5 * 60 })
@Post('/login')
What the above @RateLimiter decorator will do is limit a user to being able to log in only 5 times in a minute and reject with 429 if the user tries to log in more than 5 times. Depending on the implementation, it may follow any rate limiter algorithm, for example, token bucket [link here].
API rate limiter will save you most of the time, as these are usually triggered in any system. They also save API endpoints against rouge scripts, which has the potential to bring down the system. It is a good idea to keep some values of threshold and duration in production and development to prevent any surprises.
Websites like Amazon host flash sales where rate limits are relaxed and it is allowed to be leaky, i.e., burst briefly for a short period of time, that may be included in the implementation.
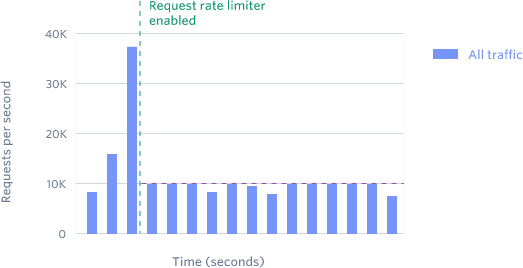
API Rate limiters, limits users to a maximum threshold of request per second.
Concurrent rate limiter
All API endpoints are not the same; some are slow and resource-hungry. Hitting the rate limit on such APIs affects the overall system performance, slowing down every low CPU usage API.
API level rate limits safeguard individual APIs, but this rate limiter makes sure to safeguard a set of APIs together to keep the system running at acceptable performance.
Current rate limiter: "You can only request 50 requests in progress at the same time.".
API Rate Limiter "You can send 1000 requests to our API endpoint."
It also forces users to think about how to manage the API requests.

Concurrent rate limiter, manage resource-contention for CPU intensive API endpoints.
Fleet usage load shedder
Load shedder rate limiting, sheds the load of low-priority endpoints by reserving a fixed fraction of resources to be always available to serve high-priority requests.
For say, it is like reserving 20% of our resources for high-priority requests and low-priority requests get 80% of system resources. In case of increased loads because of low-priority requests, we make sure that we don't compromise with percentage of resources allocated to high-priority requests. So low-priority requests will be dropped if it tries to cross 80% resource allocation with a 503.
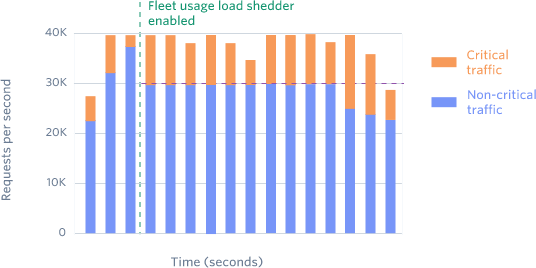
Fleet usage load shedder, make sure there are always enough resources for critical high-priority requests.
Worker utilization load shedder
API services are served by a set of worker machines that independently receive and respond to requests. In case of increased loads when many requests are getting queued up on a worker, that worker may choose to drop a low-priority request in favor of any high-priority request in the queue. Worker sheds low-priority load as its utilization limits are challenged.
This is the last defense against increased traffic loads and is rarely triggered, maybe only in major incidents.
As an example, the API endpoints can be categorized in the following fashion:
Critical request
Post request
Get request
Test script request
Track the load and utilization of the worker and when we see it is getting challenged and many requests are being queued, the worker will start shedding requests from the bottom i.e requests from test script or automation environments are dropped first with 503, and we go up in the list as required.
It is important to bring back dropped requests with delay, as it may again cause issues to be brought back immediately.
The idea here is to keep on shedding low-priority requests and trying our best to serve critical or high-priority requests as long as possible without a system shutdown, as soon as the incident is resolved we can slowly bring back traffic as per priority order to serve them back again.
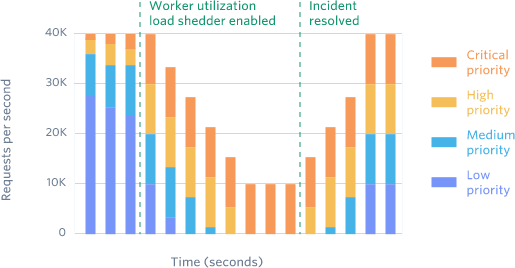
Worker utilization load shedders reserve workers for critical requests.
Conclusion
Rate Limiters are the most reliable way to accurately scale your API endpoints. Start small from the API level rate limit and gradually add others when needed.
In the real world, there are many rate limiter implementations that operate on different layers (middleware, application layer, IP layer). There are many different algorithms that rate limiters implement, keeping usage counts in Redis or something similar.
Depending on the scale of the company rate limiter can be in the API gateway, middlewares, or application layer. In any scenario, we should make sure if the rate limiter itself is down it shouldn't affect API as it is.
Intent should be relayed to rate limited/ throttled users, whether a service it is 429 or 503.
Keep metrics up to make sure you are not rejecting genuine requests and tune limits accordingly.